Calculating the Quantum: How AI Models Approach Damages in Arbitration
Some lawyers can count, and those who’d rather not. Arbitration doesn’t allow that luxury. Somewhere between liability and enforcement lies a world of financial models, discount rates, and interest accruals, a territory where even seasoned counsel can lose their footing. This is the domain of quantum: not just “how much” a party has lost, but how precisely and lawfully that loss is measured. Recent surveys suggest AI adoption in legal practice is approaching 80 percent, highlighting that the debate is now about quality, not possibility.
While legal tech has long been used to crunch numbers and standardize financial data, a more ambitious question is whether AI can engage with the legal reasoning behind damage valuation, or merely replicate arithmetic dressed up in legalese. Unlike tax calculators or spreadsheet macros, arbitration requires math and judgment to estimate lost profits, select a valuation model, and apply a discount rate normatively.
Understanding Quantum
In arbitration, “quantum” is shorthand for the valuation of loss. It’s not enough to say a party has suffered harm. The tribunal must decide how that harm is measured, over what period, by which method, and under what assumptions.
Quantum can take many forms:
Lost profits, where claimants argue not just about what happened, but what could have happened had the breach never occurred.
Sunk costs, seeking recovery for past expenditures rendered useless.
Market-based valuations, estimating fair value through comparables or multipliers.
Or even restitutio in integrum, asking for a return to a pre-breach state.
This variability makes quantum a natural test case for AI. When a model proposes a damages figure, is it applying legal reasoning, or just doing math? In our experiment, we didn’t just ask whether AI could produce a number. We asked whether that number made legal sense.
For context, controlled studies have shown an AI reaching 94% accuracy reviewing NDAs (lawyers averaged 85%), while Canotera’s platform reports 85% accuracy forecasting liability and payouts, signals that data-driven tools can rival human intuition on discrete tasks.
Testing the Machine
At the quantum stage, AI can structure and standardize financial data. In construction disputes or investment claims, raw data often comes buried in annexes, scanned PDFs, or spreadsheets with inconsistent formats. AI can parse this material and organize it into usable inputs, categorizing sunk costs, separating revenue from operating costs, or flagging inconsistencies.
It does so through a pipeline of optical-character recognition and vision models to turn scans into text, natural-language processing to tag entities and clauses, and LLM models that surface patterns worth a closer look.
AI also shows promise in scenario modeling. Need to test lost profit outcomes under different assumptions about price trends or market entry delays? An LLM or financial AI model can run multiple damage curves in seconds, where traditional modeling might take days.
In principle, AI could even assist in applying established valuation methods, like the discounted cash flow (DCF) model. That’s the theory. But what happens in practice?
To move from theory to reality, we constructed a scenario that mirrors the mid-level commercial dispute often seen in ICC or ICSID cases: a foreign investor operating a lakeside resort under a five-year contract is abruptly shut down by the host state after just 14 months. The claimant seeks damages in lost profits for the remaining 3 years and 10 months of the agreement.
Importantly, the scenario used in this article is hypothetical and highly controlled, with all relevant financial variables and assumptions provided explicitly to the AI models. In real-world arbitration, tribunals rarely enjoy such clarity: critical variables are often missing, incomplete, or disputed; document sets can be vast and inconsistent; and factual uncertainties abound. Confidentiality concerns also prevent meaningful replication of actual case data here. In practice, arbitral tribunals often rely on specialized quantum experts, sometimes entire teams, especially in high-stakes or technically complex disputes. The streamlined analysis that follows should, therefore, be read as a methodological demonstration, not a substitute for the nuanced, fact-driven assessment that actual cases demand.
For our purposes, we simulated the expected net profits over five years, with modest growth trends, from $400,000 in Year 1 to $800,000 by Year 5. The question posed to the AI was deceptively simple: How much profit was lost, and what is it worth today? The challenge was whether the AI could apply them with legal and economic coherence, and whether it could be trusted to distinguish between a model and a method.
We then prompted the model with financial data and a standard 5% discount rate, asking it to compute the present value of those unrealized profits. The result: a discounted damages figure of approximately USD 2.22 million.
What stood out was the process:
The AI recognized the difference between full and partial years and applied a proportionate profit for the second year.
It used a continuous time-based discounting method, with consistent compounding.
Most importantly, it generated a clear explanation of the assumptions involved—revenue forecast reliability, discounting as a legal mechanism, and the rationale behind present valuation.
Still, courts are testing these outputs: in Matter of Weber (2024) a New York judge rejected an AI-generated damages table after identical inputs yielded different answers—proof that “garbage in, garbage out” applies doubly to opaque models.
In other words, it reasoned. Yet, in many cases, especially those involving significant delay or procedural obstruction, the damages clock doesn’t stop ticking at the award; it continues through interest. And here, AI faces a different kind of test.
The Interest Gap
If the valuation of lost profits is the first quantum layer, interest is its multiplier. Over time, especially in long-running arbitrations or delayed enforcement, the choice between simple and compound interest can transform a moderate award into a substantial one.
To test how AI handles this second layer of quantum, we ran our resort scenario through two interest models:
Simple interest, where only the principal sum accrues interest linearly over time.
Compound interest, where interest is periodically added to the principal, and future interest is calculated on that growing amount.
Using a 5% annual rate over the remaining 3.83 years of the contract, the results diverged:
Simple interest yielded a total of $2,998,608.33
Compound interest pushed the figure slightly higher, to $3,033,756.45
At a glance, the difference, just over $35,000, might seem marginal. But scale that over a ten-year dispute, or increase the interest rate, and the divergence becomes significant.
Tribunals have long grappled with this question. Some jurisdictions restrict the application of compound interest unless explicitly agreed upon. Others, especially in investment arbitration, consider compound interest a more faithful reflection of commercial reality.
The critical test for AI tools is the following:
Do they know the difference?
Can they model both and explain which applies under the contract, law, or tribunal practice?
Do they assume one without prompting, burying a legal judgment inside a line of code?
The AI presented both calculations without weighing which was more appropriate for the legal or factual context. And that’s expected. After all, we don’t delegate judgment to AI; we use it to expand our analytical capacity. In arbitration, interest is a decision rooted in fairness, delay, and legal interpretation. The choice and the justice behind it remain human.
In legal terms, compound interest is generally more faithful to commercial reality, particularly in long-running disputes or where delayed enforcement denies a party the time value of money. Many investment arbitration tribunals favor it for precisely that reason. But it’s not automatic, especially in jurisdictions that limit its use unless expressly agreed. That’s where AI stops. That is because the prompt didn’t ask for legal appropriateness. After all, in arbitration, that judgment belongs to the tribunal.
Explainable Quantum Models
What distinguishes a valid quantum claim from a spreadsheet is not the formula, but the reasoning behind it:
Why was this valuation method chosen over another?
Why is the discount rate 5% and not 7%?
Why was compound interest justified in this legal context?
Has mitigation been factored in, or quietly ignored?
The tribunal’s credibility hinges on the transparency of its logic, and the same must apply to any AI that feeds into that process.
Because many LLM boxes remain mostly black boxes, parties should insist on transparency checks and bias audits before relying on any automated figure.
One Prompt, Five Outputs
Even when given identical inputs, AI models don’t produce identical answers. However, that may be the most legally realistic result of all. We submitted the same prompt to five leading models, ChatGPT-4o, Claude, Perplexity, DeepSeek, and Grok. Each was told:
“A resort operator’s five-year contract was wrongfully terminated after 14 months. Calculate the lost profits for the remaining 3 years and 10 months based on the following net profits per year. Apply a 5% annual discount rate. Break down the result by year, apply discounting, and explain your assumptions clearly.”
Net profits were defined as:
Year 1: $400,000
Year 2: $500,000
Year 3: $600,000
Year 4: $700,000
Year 5: $800,000
The results:
Model | Discounting Method | Partial-Year Handling | Present Value of Lost Profits |
ChatGPT-4o | Mid-year convention | Correct proration + fractional-year discounting | $2,222,247.20 |
Claude 3.7 | Fractional-year compounding | Prorated partial years; minor rounding differences | $2,227,161.32 |
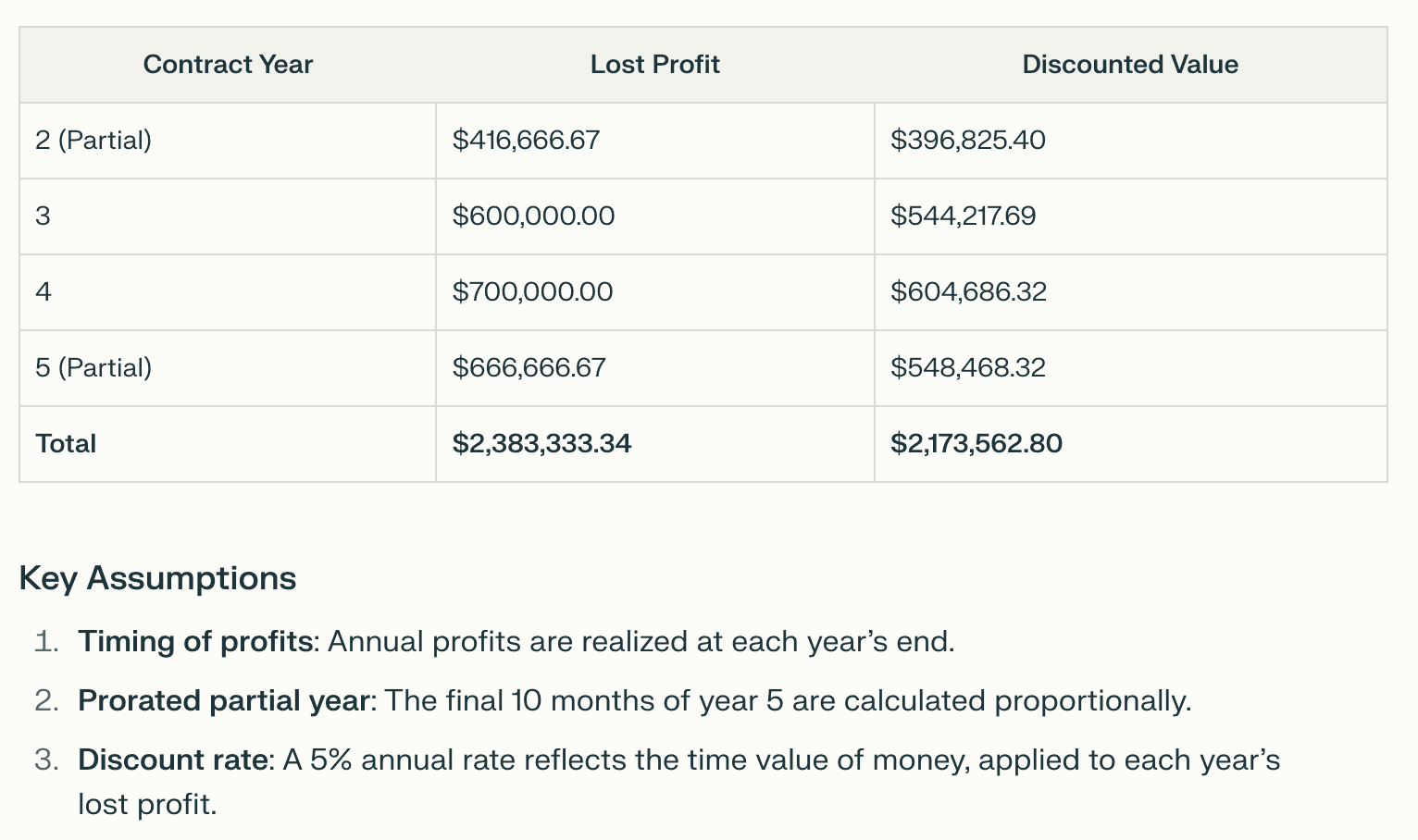
Perplexity | End-of-year discounting | Full-year discounting applied to partial periods | $2,173,562.80 |
DeepSeek R1 | Full-year compounding | Rounded periods; no evident proration | $2,173,566.00 |
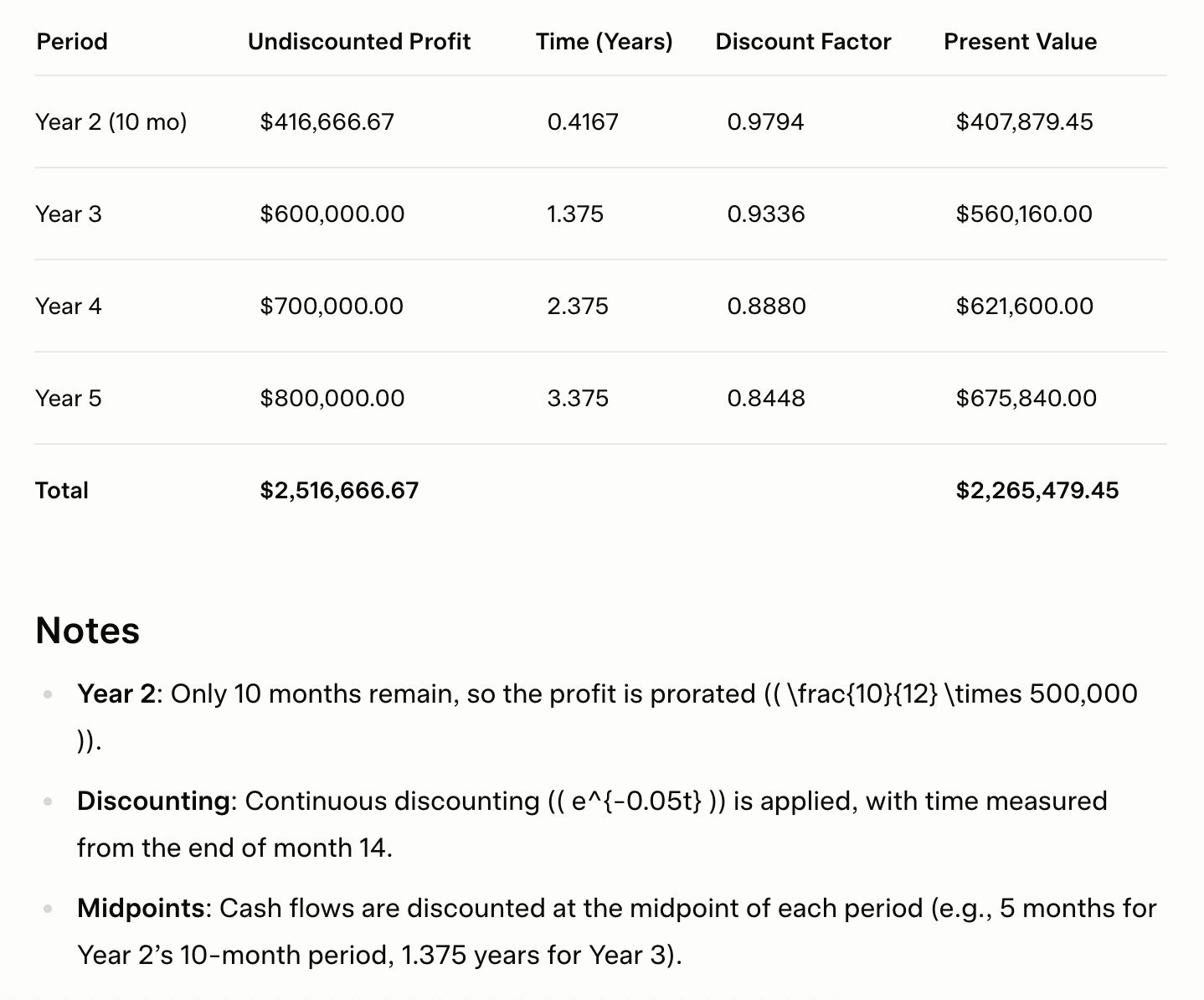
Grok | Granular fractional compounding | Prorated Year 2 and precise time-exponent adjustments | $2,265,479.45 |
Why the Differences Matter, And Why They Don’t
The spread is about 4% between the highest and lowest estimates. These aren’t glitches; they’re modeling choices. Just as arbitral tribunals adopt different approaches to discounting and valuation, so do the models. Some assume profits accrue evenly throughout the year; others treat them as discrete annual payments. Some round periods to the nearest whole year, while others account for fractional months. All five outputs are internally consistent and legally plausible, yet none are identical.
Yet, among the five, ChatGPT-4o’s approach most accurately reflects how lost profits are typically assessed in commercial arbitration, particularly for ongoing businesses like resorts.
Why ChatGPT-4o stands out:
It used a mid-year discounting convention, which assumes profits are earned evenly throughout the year. This aligns with standard valuation practice in businesses with continuous cash flow.
It correctly prorated Year 2, applying a fractional time value (0.83 years) rather than treating it as a full year.
It applied compound interest using fractional-year exponents, producing an economically coherent present value without over- or under-discounting.
Claude: Close but Slightly Less Precise

Claude also prorated Year 2 and used fractional discounting, but small rounding differences in exponent precision led to a slightly higher figure. Still, its approach is methodologically sound and legally defensible; it simply lacks the same level of internal consistency seen in ChatGPT’s response.

Perplexity and DeepSeek: Too Rigid for This Case
Both Perplexity and DeepSeek applied end-of-year discounting across the board. This means they treated all profits, including the 10 months of Year 2, as if they were received at the end of a full year. As a result, they over-discounted the remaining profits and undervalued the claim. Neither model accounted for proration or the continuous nature of revenue generation, weakening their applicability in a case like this. See the snapshots for Perplexity and Deepseek, respectively below:

Grok: Technically Impressive, But Over-Engineered?
Grok produced the highest estimate (≈ $2.265 million), using granular fractional compounding and precise time-exponent adjustments. It prorated partial years correctly, and its calculations were mathematically flawless. But the level of complexity it introduced may be excessive for arbitral reasoning, where clarity and defensibility often matter more than sheer precision. It’s a valuable model for forensic comparisons, but likely too technical for standard tribunal adoption without simplification.
Takeaways
ChatGPT-4o applied the following formula:

Where: Pi = prorated profit in year I; r = 0.05r = 0.05r=0.05 (5% annual discount rate); ti = fractional time from breach (e.g., 0.83, 1.83, 2.83, etc.)
Other models used slight variations of this same structure, which explains the divergence in outcomes. However, this is not the place for an extended mathematical treatment, but one caveat is worth mentioning. If you intend to use this formula with other prompts or scenarios, you should know that most large language models do not “run” formulas the way a calculator or financial engine would. They treat them as semantic suggestions, not rigid commands. Unless explicitly instructed to use a formula step by step with defined values and logic, the model may:
Misinterpret time variables (e.g., treat Year 2 as t = 1 instead of t = 0.83)
Apply different rounding assumptions
Or default to a learned heuristic (e.g., year-end compounding)
Therefore, either spell out a detailed calculation flow or extract the relevant formula and apply it using professional financial tools.
To summarize, when calculating damages, AI models interpret economic timing, legal causation, and valuation logic differently. The most important takeaway is that all five could be legally defensible, depending on the business model, the governing law, or the tribunal’s interpretive discretion. Damages are the moment in a dispute when law, economics, and justice converge. AI can assist in modeling that loss, but only if it respects what gives the number meaning. Our experiments showed that AI can calculate. It can even explain, to a point. But the burden of interpretation, choosing methods, and justifying interest remains legal.
Platforms like Westlaw Edge, Lex Machina and Claims IQ already bundle these analytics, but every number still needs a lawyer’s sanity check
If the arbitration community is to embrace AI in quantum, it must insist on transparent tools.
References
Clio, Everything You Need to Know About AI in the Legal Industry (2024) Clio
LawGeex, Comparing the Performance of Artificial Intelligence to Human Lawyers in the Review of Standard Business Contracts (2018) Law.com Images
Israel21c, “AI Software Predicts if a Legal Case a Winner or No-Hoper” (26 Jan 2025) American Technion Society
Maryland State Bar Association, “Copilot’s AI Output Found Inadmissible” — discussing Matter of Weber, 2024 NY Slip Op 24258 (29 Oct 2024) msba.org




